This blog post is written by Tariq Khokhar, Data Scientist and Open Data Evangelist at The World Bank, and is cross-posted from Open Data. The World Bank Data Blog.
![]()
I was lucky to be in Berlin with some colleagues earlier this month for the 2014 Open Knowledge Festival and associated fringe events.
There's really too much to distill into a short post – from Neelie Kroes, the European Commissioner for Digital Agenda, making the case for “Embracing the open opportunity” to Patrick Alley’s breathtaking accounts of how Global Witness uses information to expose crime and corruption in countries around the world.
A few things really stuck with me though from the dozens of great sessions throughout the week, here they are:
1) Open data needs users and long-term commitment from governments.
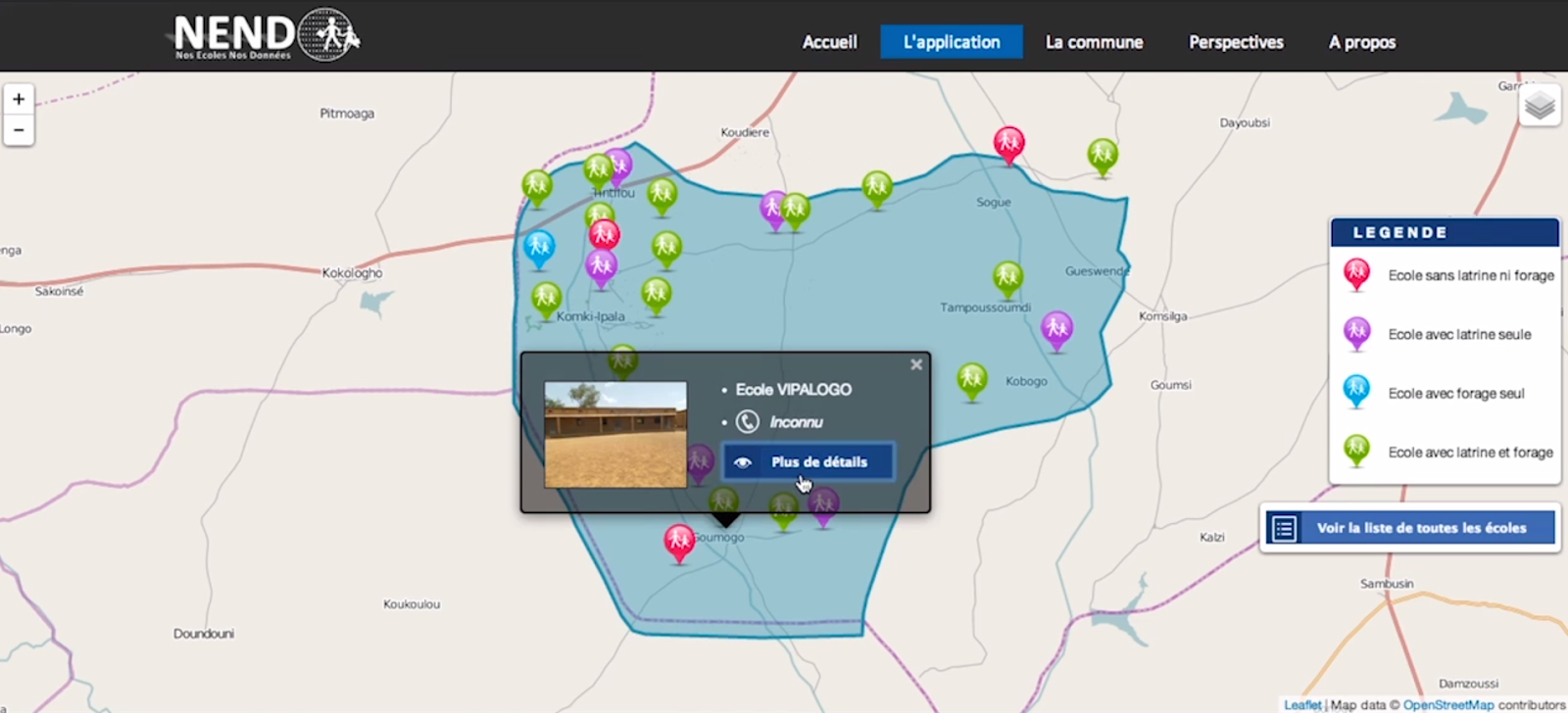
The “Nos Ecoles, Nos Donnees” Application in Burkina Faso
The Partnership for Open Data hosted a fantastic session highlighting examples of open data in action in low and middle income countries.
Tanzania
Joachim Mangilimai a School of Data Fellow from Tanzania showcased a Swahili mobile app he'd developed to support decision making by medical staff. The app was based on guidelines published by The Population Council and built using the Open Data Kit framework. He also highlighted Shule.info, a project by Twaweza that compiles and visualizes government data on school performance that parents can use to stay better informed.
Burkina Faso
Malick Tapsoba, the technical manager of the Open Data Burkina Faso team highlighted the difficulties they overcame in launching their open data portal in a low capacity, low connectivity environment and how the next big challenge was to nurture a community of data users. They'd also built a great school information app called “Our Schools, Our Data” that offers gender disaggregated data on school performance. They’ve done an impressive job of kick-starting their initiative in a difficult environment.
Mexico and The Philippines
We also heard from Ania Calderón of the Mexican government on their “Data Squads” program providing rapid support to different government agencies to publish high quality data to the national open data portal. Finally, Happy Feraran who created the Bantay corruption reporting platform in the Philippines emphasised the importance of mobilizing the community.
Lessons learned: There are some great open data initiatives around the world and two common themes are the need for a strong community of technologically literate data re-users, and the sustained effort needed within governments to change how they create, manage and publish data in the long term. Tim Davies has also shared “15 open data insights” from the Open Data Research Network, and you can read the ODI’s Liz Carolan’s takeaways from the event here.
2) Spreadsheets are code, and you can unit test data
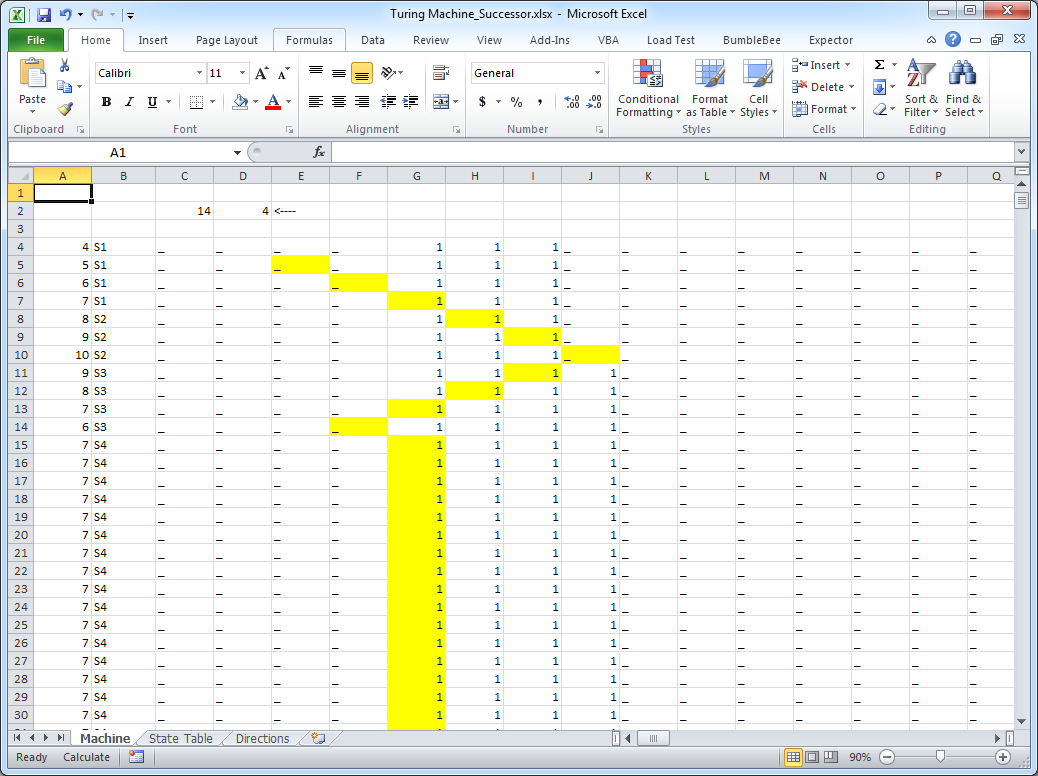
A Turing Machine implemented in Excel
Jenni Tennison has declared 2014 the year of the CSV and the fringe event csv,conf was the most informative conference I've been to in a long time. With over 30 speakers on technically specialised topics to do with the creation, management and application of (mostly) tabular data there was again too much to choose from but my highlights were on “Treating spreadsheets as code” and “Unit testing for tabular data”
Spreadsheets are code
Felienne Hermans who heads The Spreadsheet Lab (I'm not kidding) at Delft University asked that if we remember one thing from her talk it’s that “spreadsheets are code”. She thinks we should treat them as such and use software engineering approaches like tests, refactoring, and designing for maintainability. She casually demonstrated that Excel is “Turing complete” and just as powerful as any other programming language, by using it to build a Turing Machine (see picture above) and highlighting some tools that can help to improve the quality of spreadsheet applications.
The first tool is Bumblebee which Felienne developed for optimizing spreadsheet formulas. It can do a lot but think about automatically replacing things like “SUM(F3:F7)/COUNT(F3:F7)” with the simpler “AVERAGE(F3:F7)” plus other user-defined or automatic transformations. She discussed another tool (which I now forget the name of) that helps with formula testing and at the end of her talk, mentioned the (commercial) service spreadgit that brings cloud-based git-like revision management to Excel.
She noted that “Like democracy, spreadsheets are the worst, except for all others” and in her “Programming and data science for the 99%” course recognizes that Excel (and open alternatives like LibreOffice and OpenOffice) are going to be the main way most people do data analysis for the foreseeable future, so we should encourage people to adopt some good software engineering habits when coding spreadsheets.
Programatically Testing data
Karthik Ram the co-founder of the awesome rOpenSci and scientist at Berkeley shared some promising work they've been doing on the testdat R package. In short, it will let you programmatically test for and correct errors like outliers, text formatting problems and invalid values in datasets. It’s still in development but you can get an idea from Karthik’s slides.
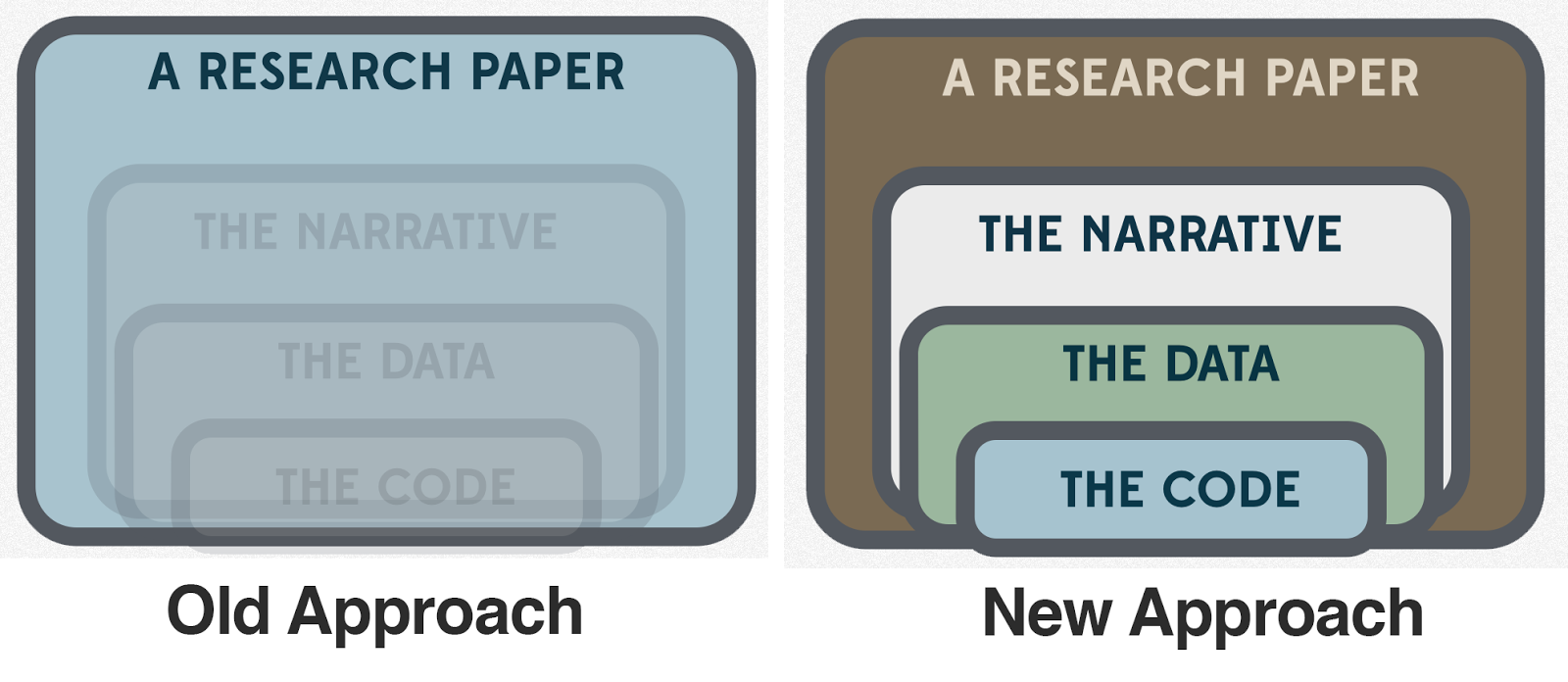
The old and new approaches to science by Karthik Ram.
He ended with a useful reminder of the changing norms the “open science” movement is creating – where once the research paper was the principal output of a scientist, it's increasingly accepted that the code, the data and separate elements of the narrative of a scientific study will all be public and available for re-use.
Lessons learned: Spreadsheets are code and we can adopt some software engineering practices to make much better use of them. There are a number of powerful tools and approaches to data handing being pioneered by the scientific community (e.g. Hadley Wickham just announced the tidyr tool for data cleaning in R) and those of us working in other fields can adopt and emulate many of them.
3) The future of civic tech (probably) lies in re-usable software components

I had a chat with the always thoughtful Tom Steinberg of mySociety just before the “Can Open Data Go Wrong?” session and Tom told me about one way he thinks open data can go right: Poplus
To use their own words, Poplus is an “open federation of people and organisations from many different countries.” with a “joint mission to share knowledge and technology that can help us to help citizens” The primary resource they've got at the moment are Poplus Components which you can think of as building blocks for more complex civic applications.
The current components are:
Represent Boundaries – a web API onto geographic areas like electoral districts
SayIt – a service to store and retrieve written transcripts of public statements
MapIt – a service that finds out which administrative area covers a specific point
WriteIt – a service to write and send messages to public persons
PopIt – a tool to keep lists of politicians and associated biographic information
BillIt – a flexible document storage tool
Why re-usable software components and not re-usable apps?
So for example, could this app built to visualize secondary school performance in the United Kingdom be re-purposed to work in Tanzania or Burkina Faso? Maybe, but probably not. Why? Because the context is different enough, that the UK-based app, like many others, just doesn't quite translate to work in other countries, so it’s just easier to build a new app designed for the local context.
This is why Poplus components are great – they abstract out functional elements of civic applications and make them easy to combine and build a more complex service on top of. Nerdier readers will remember Robert Glass' “rule of three” which states it’s three times as difficult to build reusable components as single-use components. I think Poplus understands this this and the components are carefully curated and already being re-used and combined around the world.
Lessons learned: Open data fundamentally needs open source software. App reuse often doesn't happen because contexts are too different. Reusable software components can reduce the development overhead for creating locally customized civic software applications and a pool of high quality civic software components is a valuable public good worth contributing to.
Finally, a big thank you to the organizers of OKFest and csv,conf for hosting such great gatherings. Were you at #okfest14 or #csvconf – what did you learn?